 Свежие темы
Свежие темы Войти
Войти

Парсер статей Яндекс Дзен
Данный шаблон парсит статьи и их статистику, внося данные в сформированный на лету Excel файл, создавая в нем листы с именем ключевого слова или канала для более удобного восприятия собранной информации. Шаблон парсит статьи быстро, на гет запросах!
Для каких целей будет полезен данный инструмент:
Собранные статьи вы можете использовать для постов в соц. сетях, создания дорвеев, для лонгридов ВК, ОД, Telegram и т.д.
По собранной статистики определить какие статьи пользуются большей популярностью, и на основании этой информации отбирать только интересный контент для постов. Также с помощью статистики можно отслеживать свой канал в Яндекс Дзен и вовремя реагировать на снижение вовлеченности читателей вашего канала.
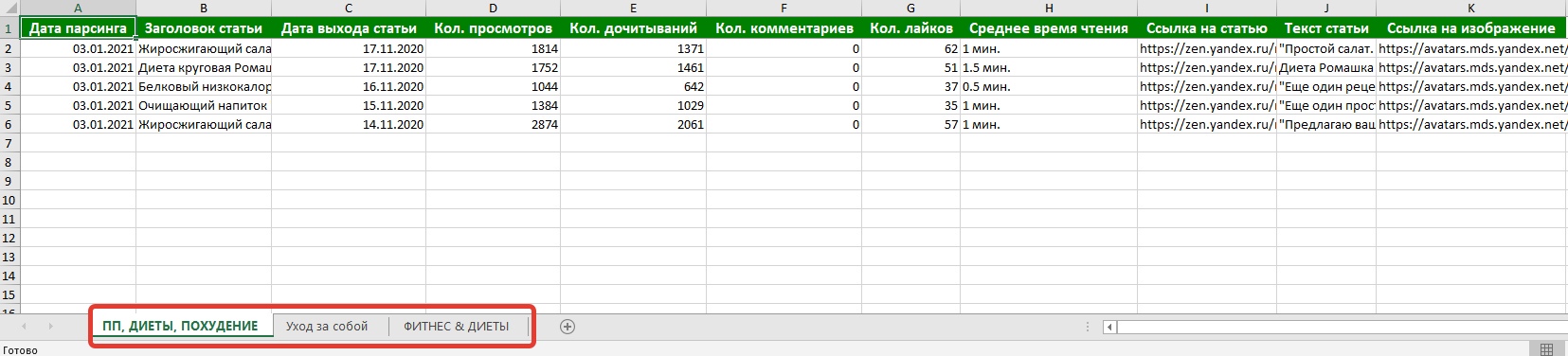
При парсинге формируется такая информация как:
— Дата парсинга статьи
— Заголовок статьи
— Дата выхода статьи
— Количество просмотров
— Количество дочитывания статьи
— Количество комментариев
— Количество лайков
— Среднее время чтения статьи
— Ссылка на статью
— Текст статьи
— Ссылка на изображения в статье
Входные настройки шаблона:
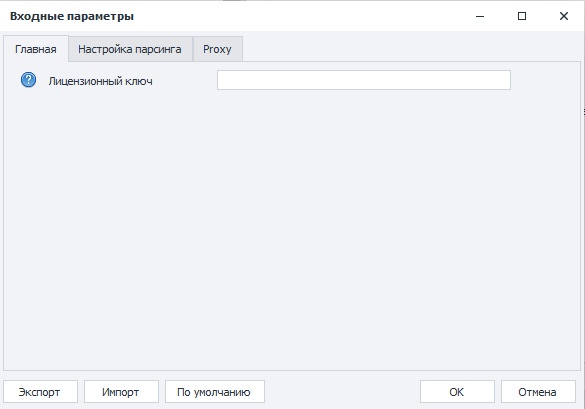
На этой вкладке указывается лицензионный ключ, полученный после приобретения шаблона. Действует пробный период - 24 часа с первого запуска шаблона. После истечения демо периода, шаблон запросит ключ, без которого он не будет работать.
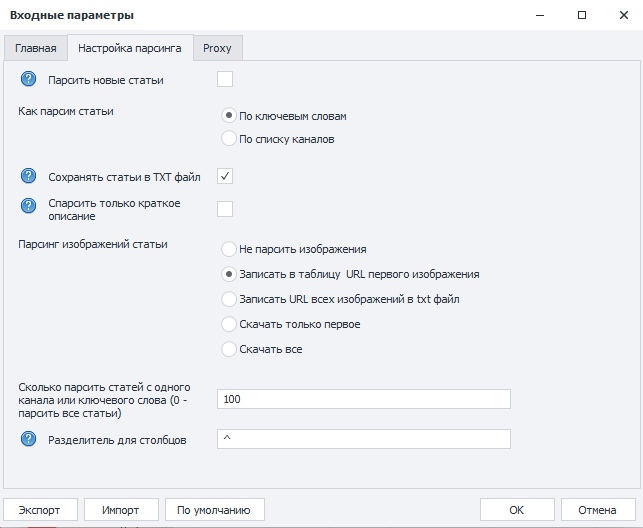
На этой вкладке выбираете режим парсинга.
1) Если поставить галочку «Парсить новые статьи» - то ранее собранные статьи не будут браться. Ссылки, на ранее собранные статьи, храняться в файле used_links_to_articles.txt, который находиться в папке Temp.
2) Есть два режима парсинга статей:
— По ключевым словам
— По списку каналов
При выборе режима «По ключевым словам» - шаблон будет брать их из файла keywords_search.txt, не забудьте перед запуском шаблона внести в этот список нужные ключевые слова! Каждое слово или словосочетание указывайте с новой строки!
При выборе режима «По списку каналов» - данные будут браться из файла chennels.txt в который вы заблаговременно внесете ссылки на каналы.
3) Поставив галочку напротив «Сохранять статьи в TXT файл» - текст статей будет сохранен txt файлы, имя файлов будет состоять из заголовка статьи. При отсутствии галочки, текст будет записан в Exsel таблицу.
4) При включенной функции «Спарсить только краткое описание» - будет собрано: Заголовок, короткое описание статьи, URL изображения, URL на полную статью, URL канала, название канала. Данные будут сохранены в таблицу result_kor_opis.xlsx.
Если поставить галочку напротив «Сохранять статьи в TXT файл», заголовок и короткое описание статьи будет сохранен в txt файл и в таблицу.
5) Парсинг изображений статьи:
Не парсить изображения – При выборе этого режима, изображения статьи не будут собраны.
Записать в таблицу URL первого изображения – Выбрав этот режим, будет спаршен и записан в таблицу URL первого изображения статьи.
Записать URL всех изображений в txt файл – При этом включенном режиме, будут собраны URL всех изображений статьи с последующим сохранением их в txt файл в директории проекта в папке название которой будет соответствовать заголовку статьи.
Скачать только первое – Будет скачано первое изображение и сохранено в директорию проекта в папке название которой будет соответствовать заголовку статьи.
Скачать все – Будут скачены все изображения статьи и сохранены в директорию проекта в папке название которой будет соответствовать заголовку статьи.
6) Сколько парсить статей - думаю и так все понятно.
7) Разделитель для столбцов - При сборе, данные для записи в файл Excel формируются в одну строку и для разнесения по столбцам используется разделитель, иногда этот разделитель может появиться в тексте статьи, что сбивает правильное разнесение данных в Excel. Если вдруг возникнут проблемы при записи данных в таблицу, нужно будет подобрать нужный символ и указать в этом поле.
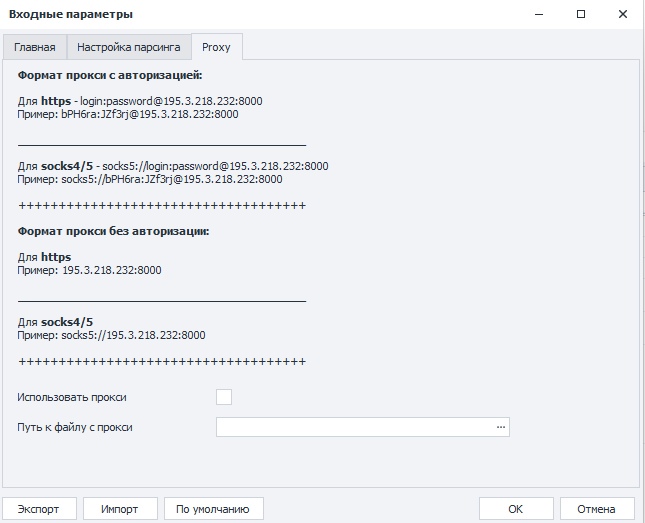
Во вкладке proxy указываете использовать прокси при работе или нет.
Файлы находящиеся в директории проекта:
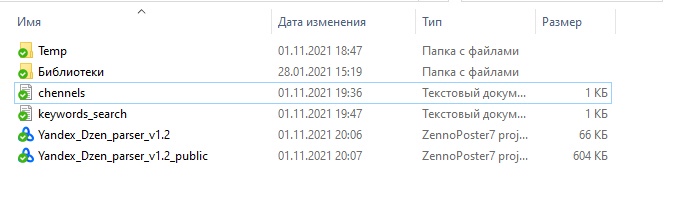
В папке Temp находятся два файла:
— Logs.txt - в который записывается информация по ошибкам, возникшим при работе шаблона для более быстрого их выявления и устранения.
— used_links_to_articles.txt - в этом файле хранятся ссылки на ранее собранные статьи
Так же в здесь есть два файла самого шаблона Yandex_Dzen_parser_v1.3 и Yandex_Dzen_parser_v1.3_public
Файл Yandex_Dzen_parser_v1.3 должен запуститься на версии ZennoPoster от 7.1.7.0 до 7.3.2.1 для нормальной работы потребуется скопировать Библиотеки из одноимённой папки в директорию Зеннопостер в папку «ExternalAssemblies» которая находиться примерно по такому пути «C:\Program Files\ZennoLab\RU\ZennoPoster Pro V7\7.3.1.0\Progs\ExternalAssemblies». У вас возможно путь до папки будет отличаться!
Если у вас версия ZennoPoster 7.4.0.0 и выше, ничего делать ненужно. Просто используйте для работы файл Yandex_Dzen_parser_v1.3_public
По файлам chennels.xtx, keywords_search.txt и proxy - думаю нет смысла повторяться.
Файл result - это Exel таблица с результатами парсинга создаётся автоматически при первом запуске или если он вдруг будет удален.
При отсутствии программы ZennoPoster можно воспользоваться ZennoBox, это обойдется +10$ к стоимости шаблона (единоразово).
Про ZennoBox можно почитать здесь.
Шаблон корректно работает только в один поток, при запуске нескольких потоков автоматически будут остановлены все потоки кроме одного для избежания ошибок!
Стоимость лицензионного ключа для шаблона 2490руб.
Для приобретения ключа пишите в сообщения группы в ВК или в Телеграм
Скачать шаблон и опробовать его в течение 24 часов можно здесь



 Парсер статей "
Парсер статей "
 Бесплатная DEMO-версия для ознакомления работы шаблона.
Бесплатная DEMO-версия для ознакомления работы шаблона. PRO-версия не имеет ни каких ограничений.
PRO-версия не имеет ни каких ограничений. Ну а сейчас не теряйте времени и быстрей опробуйте обновленный шаблон‼
Ну а сейчас не теряйте времени и быстрей опробуйте обновленный шаблон‼


